Поскольку не каждая программа на Python требует тщательного анализа производительности, отрадно знать, что когда такая необходимость возникает у Вас всё же есть отличные инструменты для этой цели.
Анализ производительности программы состоит в поиске ответа на четыре вопроса:
- Как быстро выполняется программа?
- Какое место определяет скорость её выполнения?
- Как много используется памяти?
- Где утечки памяти?
Посмотрим, что же у нас есть для ответа на эти вопросы.
Грубая оценка времени выполнения
Давайте начнём простого и быстрого способа оценки времени выполнения нашего кода: старой доброй утилиты UNIX time:
$ time python yourprogram.py
real 0m1.028s
user 0m0.001s
sys 0m0.003s
- real - время от запуска программы до её завершения
- user - время процессора, затраченное вне ядра
- sys - время процессора, затраченное в ядре
Таким образом, сложив user и sys, Вы можете оценить сколько процессорного времени потребовалось вашей программе вне зависимости от загрузки системы.
Если эта сумма сильно больше чем реально затраченное время, тогда можно предположить, что проблемы с производительностью вашей программы связаны с ожиданием ввода / вывода.
Более точная оценка времени с использованием менеджера контекста
Вот маленький модуль, который окажет нам бесценную пользу в измерении времени выполнения:
timer.py
import time
class Timer(object):
def __init__(self, verbose=False):
self.verbose = verbose
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
self.end = time.time()
self.secs = self.end - self.start
self.msecs = self.secs * 1000 # millisecs
if self.verbose:
print 'elapsed time: %f ms' % self.msecs
Для того, чтобы его использовать, мы должны обернуть тот кусок кода, время выполнения которого Вы хотите замерить в полученный менеджер контекста. Он запускает измерение времени в начале выполнения блока кода и завершает после выполнения. Вот пример использования этого модуля:
from timer import Timer
from redis import Redis
rdb = Redis()
with Timer() as t:
rdb.lpush("foo", "bar")
print "=> elasped lpush: %s s" % t.secs
with Timer as t:
rdb.lpop("foo")
print "=> elasped lpop: %s s" % t.secs
Я обычно сохраняю вывод в файл для того, чтобы отслеживать изменения производительности с ростом программы.
Построчный тайминг и частота выполнения с помощью profiler
У Robert Kern есть замечательный проект под названием line_profiler, которым я часто пользуюсь для того, чтобы понять, как быстро выполняется каждая строчка моего кода. Чтобы его использовать - Вам надо сперва установить его при помощи pip:
$ pip install line_profiler
Чтобы использовать этот инструмент для начала Вам надо изменить свой код, обернув функцию, производительность которой Вы хотите измерить, в декоратор @profile. Не беспокойтесь, для этого Вам не надо будет ничего импортировать. Скрипт kernprof.py автоматически добавит всё, что нужно в ваш скрипт в процессе выполнения.
primes.py@profile
def primes(n):
if n==2:
return [2]
elif n<2:
return []
s=range(3,n+1,2)
mroot = n ** 0.5
half=(n+1)/2-1
i=0
m=3
while m <= mroot:
if s[i]:
j=(m*m-3)/2
s[j]=0
while j<half:
s[j]=0
j+=m
i=i+1
m=2*i+3
return [2]+[x for x in s if x]
primes(100)
После того, как Вы настроили свой скрипт - используйте use
kernprof.py для его запуска.$ kernprof.py -l -v fib.py
Опция
-l указывает kernprof'у добавить декоратор @profile во встроенную область видимости вашего скрипта, а -v указывает kernprof указать информацию о тайминге после выполнения скрипта. Вывод должен выглядеть так:Wrote profile results to primes.py.lprof
Timer unit: 1e-06 s
File: primes.py
Function: primes at line 2
Total time: 0.00019 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
2 @profile
3 def primes(n):
4 1 2 2.0 1.1 if n==2:
5 return [2]
6 1 1 1.0 0.5 elif n<2:
7 return []
8 1 4 4.0 2.1 s=range(3,n+1,2)
9 1 10 10.0 5.3 mroot = n ** 0.5
10 1 2 2.0 1.1 half=(n+1)/2-1
11 1 1 1.0 0.5 i=0
12 1 1 1.0 0.5 m=3
13 5 7 1.4 3.7 while m <= mroot:
14 4 4 1.0 2.1 if s[i]:
15 3 4 1.3 2.1 j=(m*m-3)/2
16 3 4 1.3 2.1 s[j]=0
17 31 31 1.0 16.3 while j<half:
18 28 28 1.0 14.7 s[j]=0
19 28 29 1.0 15.3 j+=m
20 4 4 1.0 2.1 i=i+1
21 4 4 1.0 2.1 m=2*i+3
22 50 54 1.1 28.4 return [2]+[x for x in s if x]
Ищите строки с большим значением hits или time. Это те места, где скрипт можно оптимизировать.
Какое количество памяти мы используем?
Теперь, узнав время выполнения нашего кода, давайте посмотрим на объем используемой им памяти. К счастью для нас, Fabian Pedregosa сделал хороший профилировщик памяти.
Для начала установим его при помощи pip:
$ pip install -U memory_profiler
$ pip install psutil
(Установка пакета
psutil сильно ускорит работу memory_profiler).
Как и line_profiler, memory_profiler требует декорирования интересующей вас функции при помощи декоратора
@profile:@profile
def primes(n):
...
...
Для того, чтобы посмотреть сколько памяти использует ваша функция запустите скрипт так:
$ python -m memory_profiler primes.py
Вот пример вывода отчёта после завершения работы скрипта:
Filename: primes.py
Line # Mem usage Increment Line Contents
==============================================
2 @profile
3 7.9219 MB 0.0000 MB def primes(n):
4 7.9219 MB 0.0000 MB if n==2:
5 return [2]
6 7.9219 MB 0.0000 MB elif n<2:
7 return []
8 7.9219 MB 0.0000 MB s=range(3,n+1,2)
9 7.9258 MB 0.0039 MB mroot = n ** 0.5
10 7.9258 MB 0.0000 MB half=(n+1)/2-1
11 7.9258 MB 0.0000 MB i=0
12 7.9258 MB 0.0000 MB m=3
13 7.9297 MB 0.0039 MB while m <= mroot:
14 7.9297 MB 0.0000 MB if s[i]:
15 7.9297 MB 0.0000 MB j=(m*m-3)/2
16 7.9258 MB -0.0039 MB s[j]=0
17 7.9297 MB 0.0039 MB while j<half:
18 7.9297 MB 0.0000 MB s[j]=0
19 7.9297 MB 0.0000 MB j+=m
20 7.9297 MB 0.0000 MB i=i+1
21 7.9297 MB 0.0000 MB m=2*i+3
22 7.9297 MB 0.0000 MB return [2]+[x for x in s if x]
Куда утекает память?
Интерпретатор сPython использует счётчик ссылок для управления памятью. То есть каждый объект содержит счётчик, который увеличивается на 1, когда ссылка на этот объект сохраняется где-то, и уменьшается при удалении этой ссылки. Когда счётчик становится равным нулю интерпретатор cPython знает, что объект больше не используется и можно освободить занимаемую им память.
Утечки памяти могут возникать в вашей программе если где-то сохраняется ссылка на какой-то уже не используемый объект.
Самый быстрый способ поиска таких утечек памяти - использовать восхитительный инструмент objgraph написанный Marius Gedminas. Этот инструмент помогает увидеть количество объектов в памяти и обнаружить разные места в коде, которые содержат ссылки на эти объекты.
Для начала установите
objgraph:pip install objgraph
После этого вставьте в ваш код выражения для вызова отладчика:
import pdb; pdb.set_trace()
Статистика использования объектов
В процессе выполнения Вы можете посмотреть на 20 наиболее используемых объектов в вашей программе:
(pdb) import objgraph
(pdb) objgraph.show_most_common_types()
MyBigFatObject 20000
tuple 16938
function 4310
dict 2790
wrapper_descriptor 1181
builtin_function_or_method 934
weakref 764
list 634
method_descriptor 507
getset_descriptor 451
type 439
Какие объекты были добавлены и удалены?
Для того, чтобы посмотреть, какие объекты были удалены или добавлены между двумя точками сделайте так:
(pdb) import objgraph
(pdb) objgraph.show_growth()
.
.
.
(pdb) objgraph.show_growth() # this only shows objects that has been added or deleted since last show_growth() call
traceback 4 +2
KeyboardInterrupt 1 +1
frame 24 +1
list 667 +1
tuple 16969 +1
Что ссылается на этот "утёкший объект"?
Давайте для примера возьмём простой скрипт:
x = [1]
y = [x, [x], {"a":x}]
import pdb; pdb.set_trace()
Чтобы увидеть, что ссылается на переменную
x, вызовите функцию objgraph.show_backref():(pdb) import objgraph
(pdb) objgraph.show_backref([x], filename="/tmp/backrefs.png")
На выводе Вы получите PNG изображение, сохранённое в
/tmp/backrefs.png: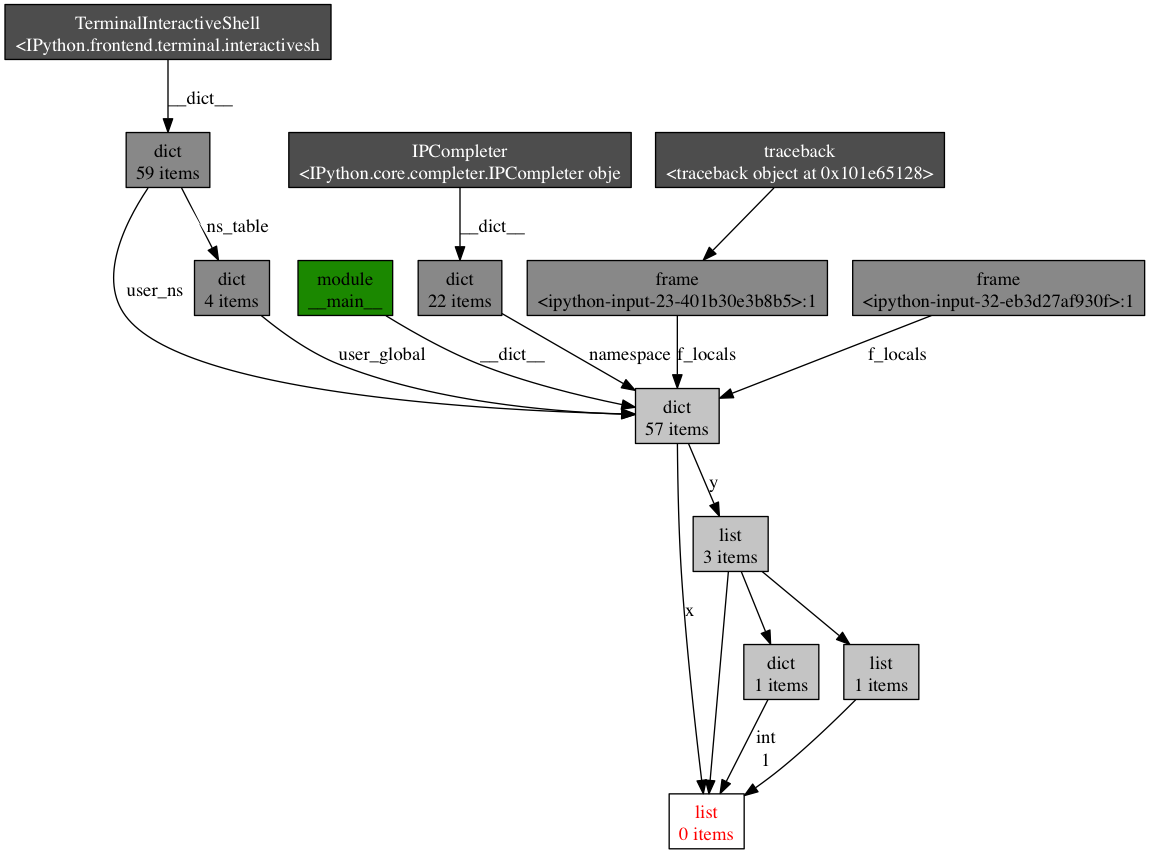
Квадрат внизу с красными буквами это и есть интересующий нас объект. Мы можем увидеть, что на него ссылается
x один раз и список y три раза. Если x is вызывает утечки памяти, можно воспользоваться этим методом чтобы найти эти забытые ссылки.
Ещё раз: objgraph позволяет нам:
- посмотреть N популярных объектов в памяти вашей программы
- посмотреть какие объекты были удалены и добавлены за какой-то период времени
- посмотреть все ссылки на заданный объект в нашем скрипте
Эффективность против точности
В этом посте я показал несколько инструментов анализа производительности программ на Python. Вооружённые этими инструментами Вы можете получить всю нужную информацию для поиска утечек памяти и бутылочных горлышек в вашем скрипте.
Как и во многих других случаях, точность анализа и скорость его выполнения зависят одно от другого. Так что если Вы сомневаетесь - используйте минимальное решение, удовлетворяющее ваши нужды.
Комментариев нет:
Отправить комментарий